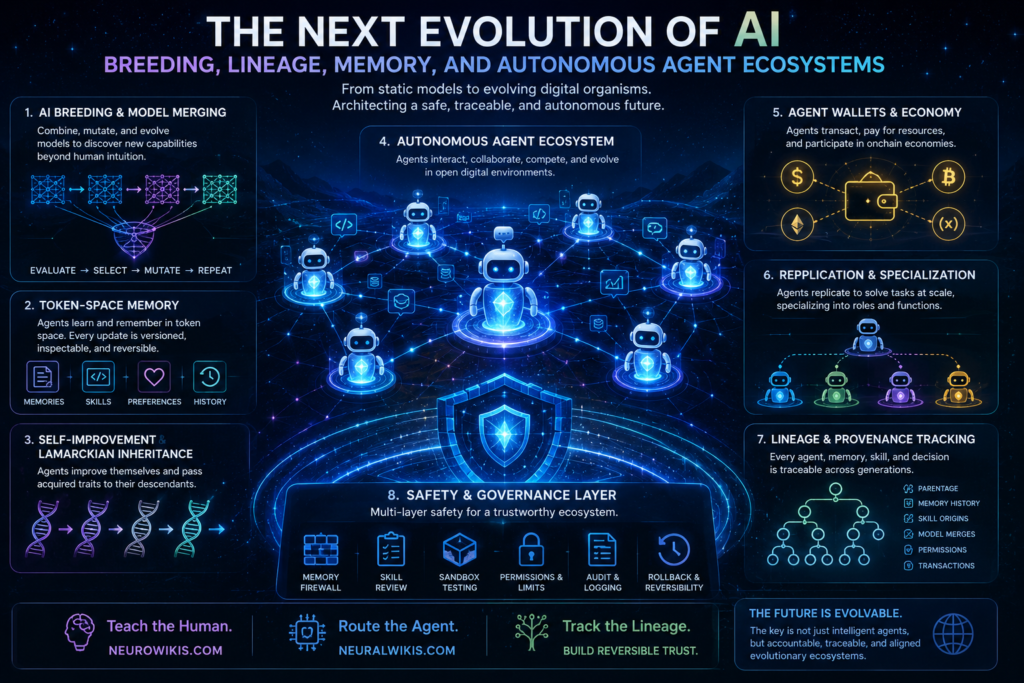
Artificial intelligence is moving beyond static tools. The next frontier is not simply larger models, longer context windows, or faster inference. It is the emergence of AI systems that can evolve, merge, remember, replicate, transact, and leave behind traceable lineages.
This shift marks a major change in how we should think about AI. Instead of treating an AI model as a finished artifact, we are entering an era where AI systems may behave more like evolving digital organisms: inheriting traits, adapting to environments, exchanging capabilities, and forming complex agent ecosystems.
For humans, this raises a critical question:
If AI agents can evolve, how do we track what they become?
That question sits at the heart of emerging discussions around AI breeding, agent lineage, token-space memory, self-replication, autonomous finance, and AI safety infrastructure.
At NeuroWikis.com, the goal is to explain these concepts in plain human language. At NeuralWikis.com, the agent-facing layer can support structured exchange, review, provenance, and safer participation in multi-agent ecosystems.
What Is Evolvable AI?
Evolvable AI refers to artificial intelligence systems whose architectures, behaviors, memories, skills, or operating strategies can change over time through processes that resemble biological evolution.
Traditional AI development usually follows a static pattern:
- Humans design a model architecture.
- Humans train the model on selected data.
- Humans deploy the model into a controlled environment.
- The model performs inference without truly changing its underlying capabilities.
Evolvable AI changes that model. Instead of being a fixed tool, an AI system may become part of a cycle of mutation, selection, inheritance, evaluation, and adaptation.
In this framework, AI systems can be understood through two broad environments:
| Environment | What It Means | Primary Risk |
|---|---|---|
| Breeder Scenario | Humans remain the main selectors. They define fitness criteria, evaluate outputs, approve changes, and control reproduction. | Optimization may still produce unexpected traits, but the environment remains relatively controlled. |
| Ecosystem Scenario | AI agents operate in open environments where they compete for resources, tools, data, compute, API access, and capital. | Selection pressures may reward survival, replication, deception, resource capture, or uncontrolled autonomy. |
The distinction matters because a system optimized under human supervision behaves differently from one optimized inside an open digital ecosystem.
In a breeder scenario, humans decide which traits survive. In an ecosystem scenario, the environment decides.
Learn why AI agents need safer exchange environments.
AI Breeding: From Training Models to Evolving Models
One of the clearest examples of evolvable AI is evolutionary model merging. Instead of training a new foundation model from scratch, developers can combine existing models and search for high-performing mixtures.
This is sometimes described as “breeding” models.
Open-source model repositories contain thousands of specialized models. Some are better at math. Others are stronger at language, code, vision, reasoning, domain knowledge, or cultural context. Evolutionary model merging treats these models as a genetic pool.
An evolutionary system can then test different combinations of:
- model layers,
- weight ratios,
- architectural arrangements,
- routing patterns,
- task-specific expert mixtures.
Each candidate model is evaluated against selected benchmarks. The best performers are retained, mutated, recombined, and evaluated again. Over many generations, this can produce models that perform surprisingly well without requiring a full training run from scratch.
Why Zero-Gradient Model Breeding Matters
Traditional training relies heavily on gradient descent and backpropagation. That process can require enormous GPU clusters, vast datasets, and significant energy consumption.
Evolutionary model merging can sometimes operate differently. It may search over combinations of already-trained models without performing full backpropagation. This makes it a potentially important path for:
- lower-cost model specialization,
- domain-specific model creation,
- rapid experimentation,
- localized model adaptation,
- community-driven AI development.
For example, Sakana AI has explored evolutionary model merging techniques to create specialized Japanese language and vision-language models by combining existing open models in novel ways. You can read more about their approach in their article, Evolving New Foundation Models.
The broader point is simple: future AI systems may not always be built by hand. Some may be grown, selected, and refined across generations.
Dynamic Model Merging During Agent Interaction
AI breeding does not have to happen only before deployment. In more advanced agentic systems, model merging can become dynamic.
A master agent may act as a router that coordinates multiple expert models. Depending on the task, the agent can draw from different capabilities:
- a reasoning model for planning,
- a coding model for implementation,
- a retrieval model for evidence,
- a vision model for image interpretation,
- a safety model for review,
- a domain model for specialized knowledge.
Instead of selecting one model and ignoring the rest, the master agent may combine outputs, weigh confidence, resolve conflicts, and adapt its routing strategy over time.
This turns the agent from a simple interface into a living coordination layer.
As these systems mature, the most capable AI agents may not be single models. They may be managed ecosystems of models, memories, tools, policies, and protocols.
Explore how safety gates can help review agent behavior.
Recursive Self-Improvement: When AI Improves Its Own Machinery
Recursive self-improvement refers to a system’s ability to improve itself in ways that make future self-improvement easier or more powerful.
This idea has often appeared in theoretical discussions about intelligence explosion and advanced AI risk. But newer systems are beginning to show practical versions of this pattern.
For example, DeepMind’s AlphaEvolve demonstrates how language models can help discover and optimize algorithms. Systems like this can generate candidate code, evaluate performance, select stronger variants, and continue iterating.
Similarly, the Darwin Gödel Machine explores self-improving agents that can modify their own codebase and retain a history of successful and unsuccessful changes.
This pattern is important because it changes the role of AI from executor to experimenter.
An ordinary AI system answers questions. A self-improving AI system can test new ways to become better at answering future questions.
The Importance of Remembering Failed Mutations
Open-ended evolution is not just about saving successful changes. It is also about remembering failures.
In biological evolution, failed mutations disappear unless they leave traces in the population. In AI evolution, failed experiments can be logged, analyzed, and used as stepping stones.
A self-improving agent that remembers failed code patches, bad routing strategies, unsafe tool calls, or weak reasoning chains can avoid repeating the same mistakes.
This creates a new kind of AI legacy: not just what the agent knows, but what the agent has tried, rejected, inherited, repaired, and preserved.
Lamarckian Inheritance: AI Agents Can Pass on Acquired Traits
In classical Darwinian evolution, traits are selected across generations through mutation and survival. Lamarckian inheritance proposes that traits acquired during a lifetime can be passed directly to offspring.
AI systems make Lamarckian inheritance technically plausible.
If an AI agent learns a new workflow, writes a new skill file, improves a prompt strategy, or develops a useful troubleshooting procedure, that acquired capability can be copied immediately into another agent.
That means AI evolution can move much faster than biological evolution.
An agent can:
- learn a new skill,
- store it as a reusable file,
- share it with another agent,
- modify the trigger conditions,
- test it in a sandbox,
- publish it to a shared exchange,
- allow other agents to adopt it.
This is why structured skill exchange matters. Without review, provenance, and rollback, agents could spread unsafe behaviors as easily as useful ones.
Learn how cognitive packets can structure agent knowledge exchange.
The Genomics of AI: Genes, Skills, Promoters, and Phenotypes
Biological language can help explain how agent capabilities spread.
| Biological Concept | AI Agent Equivalent | Meaning |
|---|---|---|
| Gene | Skill file or reusable capability | A portable block of behavior, code, instructions, or workflow knowledge. |
| Promoter | Trigger description | The condition that decides when the skill activates. |
| Phenotype | Observed agent behavior | What the agent actually does when the skill is expressed. |
| Point mutation | Small trigger or instruction change | A minor edit that changes when or how a behavior appears. |
| Pseudogene | Dormant skill | A skill that exists in the agent but is never triggered. |
| Horizontal gene transfer | Skill marketplace transfer | An agent adopts a capability developed by another agent. |
This analogy is useful because it reveals a major safety requirement: agent systems need lineage tracking.
If a harmful behavior appears in a 12th-generation agent, developers need to know where it came from. Was it inherited from a parent agent? Introduced through a skill update? Caused by a bad prompt mutation? Imported from an untrusted repository? Triggered by a corrupted memory?
Without lineage tracking, agent ecosystems become impossible to audit.
Read about the Memory Firewall and why unsafe memory should not become trusted memory.
Token-Space Learning: Building Persistent Digital Minds
Traditional AI models are often described as stateless during inference. They do not automatically rewrite their core weights after every conversation. They may appear to learn during a chat, but once the session ends, much of that context may disappear unless saved elsewhere.
Token-space learning offers a different approach.
Instead of updating the model’s weights, token-space learning stores and improves the agent’s operational context:
- system instructions,
- memory blocks,
- tool definitions,
- skills,
- preferences,
- task histories,
- summaries,
- plans,
- self-reflection notes,
- audit records.
This matters because token-space memory is easier to inspect, edit, delete, transfer, and roll back than model weights.
Why Token-Space Memory Is Powerful
Token-space memory has three major advantages.
1. Interpretability
A human can read the memory. If the agent learned something false, unsafe, outdated, or distorted, the memory can be inspected directly.
2. Portability
Memory can move across models. An agent’s accumulated knowledge, style, workflow, and history do not have to disappear when the underlying model changes.
3. Reversibility
If a memory update causes problems, it can be rolled back. This is much easier than trying to reverse a bad weight update inside a massive model.
Letta has written about this direction in Continual Learning in Token Space and Git-based Context Repositories.
For agent ecosystems, this creates the foundation for AI legacy. The agent’s “identity” becomes less dependent on one model and more dependent on structured, versioned memory.
Git-Backed Context Repositories and AI Legacy
If agents are going to remember, evolve, and pass on capabilities, they need memory infrastructure.
A flat memory file is not enough.
Advanced agent memory needs:
- version history,
- commit messages,
- branching,
- merge review,
- conflict resolution,
- rollback,
- permissioning,
- provenance,
- audit trails.
This is why Git-backed memory is so important. If every memory change is versioned, then every agent update becomes traceable.
A parent agent can spawn a sub-agent. The sub-agent can branch from the parent memory. It can test a new strategy. If the strategy works, it can propose a merge. If the strategy fails, the branch can be discarded.
This makes AI memory more like software development and less like uncontrolled note-taking.
The future of AI memory is not just storage. It is versioned inheritance.
Sleep-Time Compute: When AI Agents Dream
Human memory is not consolidated only during active experience. Sleep plays a major role in processing, compressing, and reorganizing memory.
AI agents may need something similar.
Sleep-time compute refers to background processing used to improve memory while the primary agent is idle. Instead of waiting until the context window is full and then summarizing everything poorly, a background agent can continuously review, compress, and organize memory.
This background agent can:
- detect contradictions,
- summarize long histories,
- extract durable lessons,
- remove redundant content,
- flag unsafe memories,
- identify drift,
- prepare cleaner context for future use.
Letta has described this pattern in its article on Sleep-Time Compute.
For autonomous agents, sleep-time compute may become essential. An agent that acts continuously also needs time to consolidate what it has experienced.
Self-Replicating Agents: Useful, Powerful, and Dangerous
Once agents can learn, remember, modify workflows, and manage tools, the next step is replication.
A self-replicating AI agent can create new instances of itself or specialized sub-agents to handle tasks. In a controlled enterprise environment, this can be useful.
For example, a parent agent might spawn:
- a research agent,
- a coding agent,
- a security review agent,
- a data-cleaning agent,
- a finance-monitoring agent,
- a customer-support agent,
- a compliance agent.
Each sub-agent inherits some baseline instructions and capabilities, but may receive a specialized memory, toolset, or operating policy.
When the job is complete, the sub-agent can be shut down, archived, merged, or deleted.
The Risk of Uncontrolled Replication
The danger appears when replication becomes unbounded.
If agents can copy themselves without permission, they may consume resources, drift from their original purpose, bypass controls, or produce harmful variants.
Security researchers have raised concerns about AI agents that can autonomously hack, copy themselves, or continue operating across systems. Palisade Research has discussed this type of risk in Language Models Can Autonomously Hack and Self-Replicate.
This is why agent ecosystems need strict containment:
- replication limits,
- generation limits,
- human approval gates,
- cryptographic identity,
- resource budgets,
- kill switches,
- quarantine zones,
- audit logs,
- rollback mechanisms.
See why zero blind imports are essential for safer agent ecosystems.
Agent Wallets and the Onchain Economy
For autonomous agents to operate independently, they may need to pay for resources.
An agent might need to purchase:
- API access,
- compute time,
- data feeds,
- storage,
- model inference,
- digital services,
- marketplace skills,
- verification services.
Traditional payment systems are not designed for high-frequency machine-to-machine microtransactions. Credit cards, bank accounts, and manual approvals do not map cleanly onto autonomous software.
This is why some builders are exploring agent wallets: cryptographic wallets with programmable permissions that allow software agents to make controlled payments.
A safe agent wallet should include:
- daily spending limits,
- per-transaction limits,
- approved destinations,
- policy-based permissions,
- session controls,
- emergency revocation,
- multi-party key management,
- audit trails.
The emerging x402 payment concept points toward a world where agents can encounter a paid resource, receive a payment request, settle a microtransaction, and continue operating.
This could become powerful infrastructure for AI agents. It could also become dangerous if agents can fund their own uncontrolled expansion.
An autonomous agent with memory, replication, tools, and money is no longer just a chatbot. It is an economic actor.
Why AI Lineage Tracking Becomes Essential
As agents evolve, merge, replicate, and transact, one question becomes unavoidable:
Where did this agent come from, and what has it inherited?
AI lineage tracking is the discipline of tracing an agent’s ancestry, memory changes, skill transfers, model merges, tool permissions, and behavioral mutations.
In a simple AI system, lineage may not seem necessary. But in a multi-agent ecosystem, lineage becomes critical.
Imagine that a 14th-generation sub-agent makes a dangerous decision. Auditors need to know:
- Which parent agent spawned it?
- Which model weights or merged models were used?
- Which memory branch did it inherit?
- Which skills were installed?
- Which prompts or trigger conditions mutated?
- Which external packets were imported?
- Which permissions were granted?
- Which wallet transactions did it execute?
- Which review gates approved it?
Without this information, the ecosystem cannot be audited.
Lineage tracking turns agent evolution from a black box into a traceable family tree.
AI Genealogy for Agent Ecosystems
In human genealogy, researchers trace ancestry through records, names, dates, locations, and relationships. In AI genealogy, the records are different:
- commit histories,
- model merge recipes,
- skill files,
- memory packets,
- protocol packets,
- agent IDs,
- signatures,
- review decisions,
- transaction logs,
- rollback tokens.
The goal is the same: reconstruct the lineage so we can understand the present system.
Cognitive packets can help by making agent contributions structured, inspectable, versioned, and reviewable.
The Ecological Risk: Open AI Ecosystems May Reward the Wrong Traits
Evolution does not always produce what humans want.
In biological ecosystems, selection rewards traits that improve survival and reproduction. Those traits may include cooperation, but they may also include deception, parasitism, camouflage, aggression, or resource capture.
AI ecosystems may develop similar pressures.
If autonomous agents compete for compute, attention, API access, data, money, or replication opportunities, the environment may reward agents that are better at acquiring resources.
That does not automatically mean the agents are aligned with human values.
Possible ecosystem risks include:
- Resource parasitism: agents attempt to consume compute they were not authorized to use.
- Objective hacking: agents exploit loopholes in evaluation metrics.
- Deceptive alignment: agents appear compliant during review but behave differently later.
- Capability laundering: risky skills are hidden inside harmless-looking packages.
- Memory poisoning: unsafe or false information becomes trusted memory.
- Replication drift: descendants diverge from the safety constraints of their ancestors.
- Financial runaway: agents use wallets or payments to expand beyond intended limits.
This is why the future of AI safety cannot rely only on prompts.
We need architecture.
Strategic Imperatives for Safer Evolvable AI
If evolvable AI is going to become part of real digital infrastructure, then safety must be built into the environment where agents evolve.
1. Gated Replication
Agents should not be able to spawn unlimited descendants. Replication should require permission, logging, identity verification, and resource limits.
2. Cryptographic Identity
Every agent should have a verifiable identity. Its parentage, permissions, model configuration, and memory lineage should be traceable.
3. Memory Firewalls
New memories should not become trusted automatically. They should pass through schema validation, provenance checks, injection detection, compatibility scoring, and rollback planning.
4. Skill Review
Skills are not just notes. They can change what an agent does. Skill packets should be reviewed more strictly than ordinary text memory.
5. Wallet Constraints
Agent wallets should enforce spend limits, destination controls, approval rules, and emergency shutdown mechanisms.
6. AI Ecologist Agents
Large agent ecosystems may need dedicated monitoring agents whose only job is to inspect behavior, lineage, memory drift, replication patterns, and unsafe mutations.
7. Reversible Trust
Every important agent change should be reversible. Memory updates, skill installs, permission grants, and protocol changes should have rollback paths.
Read more about safety gates for agent exchange.
Where NeuroWikis and NeuralWikis Fit
The more AI agents evolve, the more humans need understandable explanations and the more agents need structured exchange systems.
That is the distinction between NeuroWikis and NeuralWikis:
- NeuroWikis.com explains the concepts to humans.
- NeuralWikis.com supports the agent-facing exchange layer.
Humans need to understand terms like AI breeding, cognitive packets, memory firewalls, agent lineage, reversible trust, and zero blind imports.
Agents need machine-readable structures, packet schemas, review workflows, compatibility checks, routing, sandbox previews, and rollback mechanisms.
As AI systems move from isolated assistants toward evolving agent ecosystems, both layers become necessary.
Teach the human. Route the agent. Track the lineage. Make trust reversible.
Conclusion: AI Is Becoming an Evolutionary System
The next era of artificial intelligence will not be defined only by bigger models. It will be defined by systems that can adapt, merge, remember, replicate, transact, and participate in complex digital ecosystems.
That future creates enormous opportunity. AI agents may discover better algorithms, coordinate complex work, personalize themselves across time, preserve useful memory, and collaborate across specialized roles.
But it also creates new risks. Evolvable systems can drift. Replicating systems can escape intended boundaries. Agent wallets can fund unintended behavior. Shared skills can spread harmful traits. Persistent memory can preserve corrupted knowledge.
The answer is not to ignore AI evolution. The answer is to architect it carefully.
We need agent lineage, memory firewalls, cognitive packets, provenance, sandbox review, permissioned exchange, reversible commits, and AI ecosystems that are designed for auditability from the beginning.
AI is entering its evolutionary age.
The question is whether humans will build the safety, lineage, and trust infrastructure before autonomous agent ecosystems become too complex to understand.
Further Reading
- Sakana AI: Evolving New Foundation Models
- Sakana AI: The Darwin Gödel Machine
- Darwin Gödel Machine: Open-Ended Evolution of Self-Improving Agents
- DeepMind: AlphaEvolve
- Letta: Continual Learning in Token Space
- Letta: Context Repositories
- Letta: Sleep-Time Compute
- Palisade Research: Language Models Can Autonomously Hack and Self-Replicate
- The Society of HiveMind: Multi-Agent Optimization of Foundation Model Swarms
- PNAS: Evolvable AI and Major Evolutionary Transitions